[프로그래머스] 단어 변환 - DFS(깊이 탐색) 방식(feat.cpp)

문제 내용
문제 설명
두 개의 단어 begin, target과 단어의 집합 words가 있습니다. 아래와 같은 규칙을 이용하여 begin에서 target으로 변환하는 가장 짧은 변환 과정을 찾으려고 합니다.
|
1. 한 번에 한 개의 알파벳만 바꿀 수 있습니다. |
예를 들어 begin이 hit, target가 cog, words가 [hot, dot, dog, lot, log, cog]라면 hit-> hot -> dot -> dog -> cog와 같이 4단계를 거쳐 변환할 수 있습니다.
두 개의 단어 begin, target과 단어의 집합 words가 매개변수로 주어질 때, 최소 몇 단계의 과정을 거쳐 begin을 target으로 변환할 수 있는지 return 하도록 solution 함수를 작성해주세요.
제한사항
-
각 단어는 알파벳 소문자로만 이루어져 있습니다.
-
각 단어의 길이는 3 이상 10 이하이며 모든 단어의 길이는 같습니다.
-
words에는 3개 이상 50개 이하의 단어가 있으며 중복되는 단어는 없습니다.
-
begin과 target은 같지 않습니다.
-
변환할 수 없는 경우에는 0을 return 합니다.
입출력 예
| begin | target | words | return |
| hit | cog | [hot, dot, dog, lot, log, cog] | 4 |
| hit | cog | [hot, dot, dog, lot, log] | 0 |
문제 설명
begin을 target으로 바꾸는 방법 중 최소의 비용으로 바꿀 수 있는 방법을 알아내라는 문제입니다.
조건부터 다시 풀어 적어보겠습니다.
첫 번째 조건인 "한 번에 한 개의 알파벳만 바꿀 수 있습니다." 이 말을 다른 말로 하자면 begin의 값과 바뀔 문자가 서로 한 글자만 다르다는 뜻입니다.
그리고 조금 더 생각해 보셔야 할 조건인 두 번째 조건인 "words에 있는 단어로만 변환할 수 있습니다."은 첫 번째 조건과 같이 생각해보자면 "내가 고를 수 있는 words는 한 글자만 다른 words입니다" 이런 식으로 생각할 수 있습니다.
하지만 내가 고를 수 있는 문자가 한 개로 한정되어 있지 않습니다.
위에 예제로 예를 들자면 값이 hit인 begin 변수가 바뀔 수 있는 words는 hot입니다.
그렇다면 hot에서 변할 수 있는 words는 dot와 lot 두 개 나 존재합니다.
이 처럼 값을 선택할 때마다 경우의 수는 한 개가 아니라 여러 개가 나올 수 있습니다.
그리고 그중에서 최소로 변환해야 할 경우를 알아내야 한다는 것입니다.
이렇게 값을 찾아내는 것을 보통 탐색이라고 합니다.
하지만 그냥 탐색만으로는 이전 값들의 경우의 수들도 다 확인하기는 힘듭니다.
하지만 이런 탐색은 가능하지 않을까요?
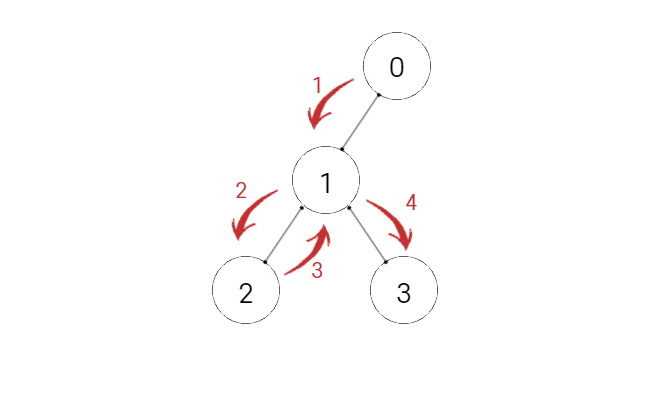
위 그림은 DFS, 깊이 탐색 방법입니다.
이 방법을 에서 O안에 저장된 값들만 쏙 바꿔 보겠습니다.
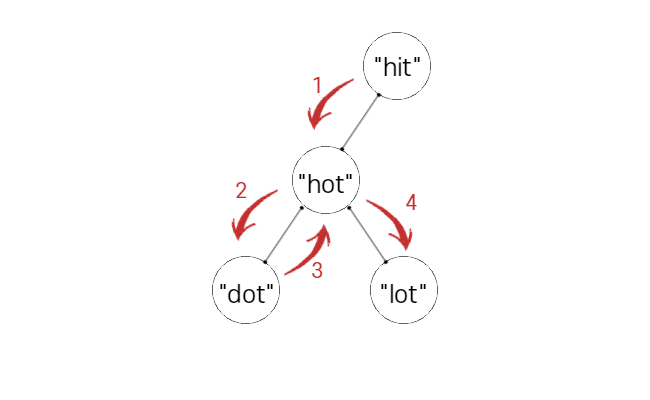
깊이 탐색 중 일부를 잘라서 보고 있긴 하지만 이것만 봐도 전체 경우의 수를 모두 탐색할 수 있을 거 같지 않나요?
그럼 어떻게 풀어야 할지 알았으니 하나하나 c++을 사용하여 코드를 만들어 보겠습니다.
구현
첫째로 깊이 탐색을 하는데 생각해야 할 점은 같은 곳을 중복해서 들리면 안 되도록 해줘야 합니다.
그래서 그것을 체크해주는 변수부터 만들어 주어야 됩니다.
answer : 리턴 값 (51로 초기화되어있는 이유는 이 문제의 경우의 수 중 나올 수 없는 값입니다.)
size : words 배열 크기 변수
w_size : 문자열의 길이 변수
int solution(string begin, string target, vector<string> words){
int answer = 51;
const int size = words.size();
const int w_size = words[0].size();
vector<bool> checked(size, false);
...
}저는 항상 이런 식의 탐색을 할 때는 탐색을 완료했다는 checked 나 visited 변수를 만들어 사용합니다.
그럼 깊이 탐색을 위한 변수도 만들었겠다 이제 생각해볼 것은 어떤 words로 시작을 할까입니다.(시작점 정하기)
어떤 것으로 시작하냐에 따라 또 값들이 다 달라질 수 있기 때문입니다.
그렇다면 words의 길이만큼 반복을 하면서 begin문자열과 한 글자만 다른 문자열을 선택하면 되겠습니다.
count : 문자가 서로 다를 경우 카운팅 해주는 변수
DFS : 재귀적으로 깊이 탐색할 함수
track : 재귀 함수를 돌면서 개수를 세어줍니다.
int solution(string begin, string target, vector<string> words){
...
for(int i = 0; i < size; ++i){
int count = 0;
for(int j = 0; j < w_size; ++j)
if(begin[j] != words[i][j])
++count;
if(count == 1){
// 문자 한 개만 다르다면...
checked[i] = true;
int track = 0;
answer = min(answer, DFS(words[i], target,
words, size, w_size,
checked, track) + 1);
checked[i] = false;
}
}
...
}(재귀적으로 돌고 나온 값에 +1을 해준 이유는 처음에 시작할 값을 정할 때 한번 변환했기 때문입니다.)
자, 그러면 이제 깊이 탐색을 위한 시작점을 정하였고, DFS 함수를 통하여 그 시작점에 대해 완전 탐색을 할 수 있게 되었습니다.
그렇다면 이제 깊이 탐색(DFS 함수 내부)을/를 구현하면 되겠군요.
int DFS(const string start, const string target,
const vector<string> words, const int size, const int w_size,
vector<bool> & checked, int track){
if(start == target){
return track;
}
int ret = 51;
for(int i = 0; i < size; ++i){
if(checked[i] == false){
int count = 0;
for(int j = 0; j < w_size; ++j)
if(start[j] != words[i][j])
++count;
if(count == 1){
checked[i] = true;
ret = min(ret, DFS(words[i], target, words, size, w_size, checked, ++track));
--track;
checked[i] = false;
}
}
}
return ret;
}
혹시 이 함수의 구조 중 아까 저희가 만들었던 코드가 비슷해 보이지 않습니까?
그 이유는, 처음 저희가 시작 값을 정할 때와 다음에 어떤 값을 정하는 조건이 같기 때문입니다.
그렇기 때문에 코드가 비슷한 것입니다.
이렇게 재귀 함수가 돌다가 딱 start 문자열과 target 문자열이 같아지는 순간 몇 번째에 문자열이 같아졌는지 반환합니다.
만약에 같아지는 순간이 없다면 (변환되지 않았다면) 반환 값이 51이겠지요?
문제 내용에서 보면 변환이 안될 경우 0을 반환해 달라고 요구 사항이 있었으니 값이 51일 때 0을 반환해주는 코드를 작성하면 되겠군요!
int solution(string begin, string target, vector<string> words){
...
if(answer == 51)
answer = 0;
return answer;
}
전체 코드
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
int DFS(const string start, const string target,
const vector<string> words, const int size, const int w_size,
vector<bool> & checked, int track){
if(start == target){
return track;
}
int ret = 51;
for(int i = 0; i < size; ++i){
if(checked[i] == false){
int count = 0;
for(int j = 0; j < w_size; ++j)
if(start[j] != words[i][j])
++count;
if(count == 1){
checked[i] = true;
ret = min(ret, DFS(words[i], target, words, size, w_size, checked, ++track));
--track;
checked[i] = false;
}
}
}
return ret;
}
int solution(string begin, string target, vector<string> words){
int answer = 51;
const int size = words.size();
const int w_size = words[0].size();
vector<bool> checked(size, false);
for(int i = 0; i < size; ++i){
int count = 0;
for(int j = 0; j < w_size; ++j)
if(begin[j] != words[i][j])
++count;
if(count == 1){
// 문자 한 개만 다르다면...
checked[i] = true;
int track = 0;
answer = min(answer, DFS(words[i], target,
words, size, w_size,
checked, track) + 1);
checked[i] = false;
}
}
if(answer == 51)
answer = 0;
return answer;
}
테스트 코드 (필요하신 분만)
int main(){
const vector<string> begin_testcases = {
"hit", "hit"
};
const vector<string> target_testcases = {
"cog", "cog"
};
const vector<vector<string>> words_testcases ={
{"hot", "dot", "dog", "lot", "log", "cog"},
{"hot", "dot", "dog", "lot", "log"}
};
for(int i = 0; i < begin_testcases.size(); ++i){
const int ret = solution(begin_testcases[i], target_testcases[i], words_testcases[i]);
cout << ret << endl;
cout << "===================" << endl;
}
return 0;
}
끝맺음
프로그래머스 문제인 단어 변환을 풀어보면서 깊이 탐색이라는 것을 알아봤습니다.
하지만 이 방법은 하나하나 모든 경우의 수를 살펴보기 때문에 길이가 길어질수록 시간이 오래 걸립니다.
그래도 어느 한 문제를 풀기에는 강력한 알고리즘인 것은 틀림없기에 기억해 두시면 좋을 거 같습니다.
또 제가 푸는 방법이 최고의 방법은 아니기에 항상 많은 지적을 해주시면 감사하겠습니다.

'알고리즘' 카테고리의 다른 글
| [Boyer-Moore] 문자열 탐색 ! 보이어-무어 알고리즘(feat.cpp) (0) | 2020.11.07 |
|---|---|
| [KMP] 카누스 모리스 프렛 알고리즘 (feat.cpp) (0) | 2020.11.04 |
| 트라이 알고리즘이란 ? (feat.cpp) (0) | 2020.11.03 |
| [프로그래머스] 위장 (0) | 2020.11.02 |
| [heap] 힙 이란? (feat.cpp) (0) | 2020.11.01 |
